Welcome to Part II of my series on ML-Agents in Unity. In the last part I got a simple model working that allowed two armies of soldiers to fight each other, however, they weren't actually trying to win. In this part, I will be working towards that goal.
Adjusting Rewards
In part I, I had been rewarding my agents for both being victorious and each time they dealt damage to the enemy. Eventually I removed the victory reward to simplify things and push the agents to get into combat. Now I tried adding victory rewards again to see what happens. I tried several variations on reward values, each with a different hit reward (That is, the reward for each individual attack that hits an enemy). Below you can see the resulting scores, they are:
- No victory reward and 1.0 hit reward
- 1.0 victory reward and 0.3 hit reward
- 1.0 victory reward and 0.1 hit reward
- 1.0 victory reward and no hit reward
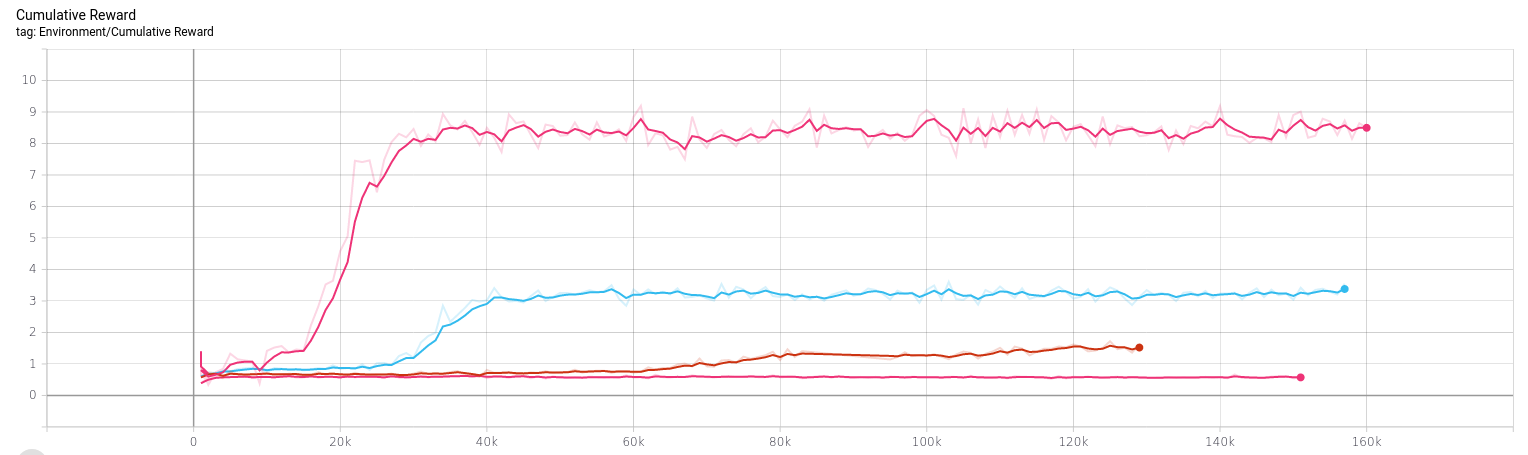
As you can see, the runs with a lower hit reward result in a lower peak total reward. This is as-expected, since each hit is worth less the total reward is less. What's more interesting is that as I reduce the hit reward the convergence to the final reward takes longer, with the no-hit-reward version failing to increase at all. Furthermore, the agent behaviour is exactly the same as in article 1: they fight, but they don't try to win.
There are two possible reasons for this that crossed my mind at this point, either
- The way I am training the agents is unable to learn a wining strategy
or
- There is no winning strategy
In order to narrow down the problem, I made a modification here to ensure that a winning strategy exists. I made the following change: when a soldier is near another soldier they both benefit from mutual-defence, getting 50% resistance to damage for each nearby soldier! So if a soldier is near one ally it will only take 50% damage, and if near two allies it will take only 25% damage and so on. With this change there is now, obviously, a winning strategy: simply stick together in a blob.
So I did further training, to see if it learned now:
It didn't, what's wrong?
Using Self-Play
The issue is that when using reinforcement learning, training works by tring to maximize the average reward. Since all the soldiers are training the same model together it means that if one side gets an advantage it increases that side's score, but correspondingly decreases the other side's. In gambling terms it would be like putting an equal bet on each side: it's never gonna lose, but also never gonna win.
I need a way to make each side train independently, to do that each side needs to count its rewards separately. But I still want the agent to be able to play against itself so it gets better over time. So what I need to do is to train one team (red team) and then after each round copy its data to the other team (blue team). The second (blue) team never actually trains it just receives copies from the red team, this way the blue team's reward doesn't affect the final outcome.
Even if I do this, there is still a problem of overfitting: the agent may become so focused on beating it's own strategies that it becomes unable to defeat more varied strategies. To ensure this doesn't happen rather than just copying the strategy that the agent played last round, I save the agent's data at various points throughout training and then chose a random one as the opponent to train against.
Now, that's all well and good, but it sounds like an awful lot of work, fortunately the same day I got to this point in the process Unity released a wonderful blog article on self-play in ML-Agents, the detailed documentation is here. With that in mind, I got started.
First I needed to make a lot of changes involving upgrading ML-Agents to the latest version, this involved:
- Upgrade ml-agents to 0.14.1
- Upgrade baracuda to 0.5.0
- Delete my Academy class (They are now singletons, and I wasn't really using it)
- Add a
DecisionRequestorcomponent to my agent to allow it to self-update (It doesn't do that by default anymore) - Take note of the fact that a 'step' in the tensorboard output is now just a single step for a single agent in the scene, before a step included one step for each agent in the scene, so I must increase my max-steps accordingly, since I have 10 agents in the scene I am going from 500,000 steps to 5,000,000 steps.
I also got rid of the team-shuffling from the first article, it again, wasn't really used.
Now, that simply upgrades to the new ML-agents, to make use of the self-play feature I must:
- Set the agent's
Team IDvariable correctly - Add a 'loss' condition with a -1 reward (Just best practice, not strictly required)
- Add a self-play block to my hyperparameter configuration
The self-play block is as-follows:
self_play:
window: 10
play_against_current_self_ratio: 0.5
save_steps: 50000
swap_steps: 50000
With all that done it's time to go ahead and train this.
Self-play results
Unfortunately, training didn't initially go as planned, the first run gave me this same senselessly aggressive behaviour as before:
After running this I went through a series of practical issues (bugs) including:
- Forgetting to actually save the file with the self-play block above
- Not setting the rewards correctly
- Not actually calling the agent's "Done" function on winning agents (And I was doing this in part I too, blind luck that it worked at all!)
- Not having an acceptable maximum length of each round (The early rounds sometimes took a very long time, which was wasteful)
- Incorrectly handling updates on 'dead' agents
Each time I went through one of these issues (Of which there are more than the above) it involved a many-hour long training run. Slowly, I managed to get behaviour that converged towards a type of "Spiralling tactic". I didn't notice it so much in the earlier runs, but after an 5.5 hour run it became clear that this behaviour was emerging. This was really interesting to me because it's clear the AI was learning something, but also something I didn't expect and cannot explain. Unexpected emergent behaviour is one of the coolest things to see in AI so I was really excited.
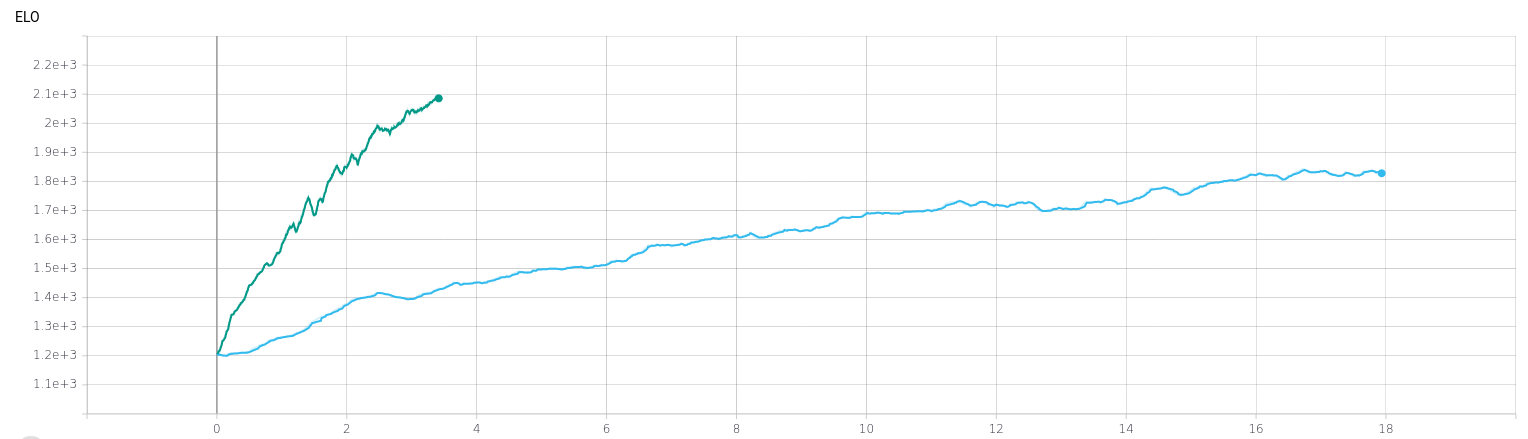
Since I now knew that the AI was actually learning I went back to my simulation parameters and increased the radius in which having an ally reduces damage taken. Since it was getting late I let this train overnight, and when I woke up it had trained for eighteen hours and resulted in this:
Beautiful! But about the time it took to train... 18 hours might be acceptable for overnight training of a fancy production model, it might even be okay for a in-development model that is well-understood, but for just messing around trying to figure things out like what I'm doing here it's far too long. Fortunately, there was a simple way to accelerate this.
By switching to running standalone builds rather than running inside the Unity editor, I was able to run at 3x the time acceleration and also run 8 instances of the training at once. Theoretically that should be 3x8=24x faster! In practice though it was only 6x faster (At some point I ought to go back and optimize this) though this is still good enough for me! This cut my previous 18hr run (Which effectively limited me to one run/day) to a mere 3 hours (Which can be done 3-4 times a day). Also, since I can now practicly run this in daylight hours rather than overnight I can now early abort if I notice it's failing early on, allowing me even more time to iterate.
After things were running nice and faster, I did a few slight tweaks. I didn't like how the soldier's were acting overly defensive, even when they had a big advantage (3 on 1 or so). I speculated this was because they only had information on where enemies are, and not a clear picture of how many enemies there are. To resolve this I added the following observations:
- My agent's own health
- How many allies are alive
- The average health of my allies
- How many enemies are alive
- The average health of my enemies.
With this in place, another run of 3 hours got me to this result:
As you can see, they have the behaviour I was looking for, and when one side gains an obvious advantage they go in for the kill
With that at this point I'm kinda happy with it for the time being. And since I have iterated over the codebase of this quite a few times in this process it has become kinda messy. I'm gonna put this aside for now and try to work on another problem for my next article!
Thanks for reading!